Formulare in Sekunden ausgefüllt, nicht Stunden

Contributors

Geschätzte Implementierungszeit
Verwendete Bibliotheken
- @operaide/ai
- @operaide/aktor
- zod
LLM-Anbieter und -Modelle
- Azure GPT-4o-mini
- Configurable via settings
Externe Dienste
- None
TAGS
Introduction
Lade ein PDF-Formular hoch und lass es automatisch mit deinem Unternehmenswissen ausfüllen — Steuer-IDs, Zertifizierungen, Adressen, Referenzprojekte und alles weitere. Die KI liest das Dokument, extrahiert jedes Feld und gleicht es mit gespeicherten Unternehmensdaten ab. Ausschreibungen, Compliance-Fragebögen oder wiederkehrende Behördenformulare, die früher Stunden dauerten, sind in Sekunden bereit zur Überprüfung.
Business Impact
Herausforderung
Unternehmen füllen wiederholt dieselben Formulare aus — Ausschreibungen, Compliance-Fragebögen, Behördenanträge — und geben dabei manuell Unternehmensdaten ein, die bereits irgendwo in der Organisation existieren.
Lösung
Eine KI extrahiert Formularfelder aus hochgeladenen Dokumenten, gleicht sie mit in der AgentDB gespeichertem Unternehmenswissen ab und füllt Werte automatisch mit Konfidenzwerten aus.
Ergebnis
Wiederkehrende Formulareinreichungen gehen von stundenlanger manueller Dateneingabe zu einer schnellen Überprüfung KI-ausgefüllter Felder — Unternehmenswissen wird automatisch wiederverwendet.
Funktionsweise
- Dokument-Feldextraktion — Lade ein PDF oder Dokument hoch. Die KI liest den Inhalt, identifiziert jedes Formularfeld und extrahiert Bezeichnungen, Typen, Werte und Gruppierungen in ein strukturiertes Format — bereit zur automatisierten Verarbeitung.
- Auto-Ausfüllen aus Unternehmenswissen — Die extrahierten Felder werden mit deinen gespeicherten Unternehmensdaten abgeglichen — Adressen, Steuer-IDs, Zertifizierungen, Referenzprojekte und mehr. Jedes Feld wird automatisch mit Konfidenzwerten ausgefüllt, damit du weißt, was überprüft werden sollte.
- Seite-an-Seite-Vergleich — Sieh die Original-Extraktion und die KI-ausgefüllten Ergebnisse nebeneinander, was Überprüfung, Korrektur und Freigabe vor der Einreichung erleichtert.
- Konfigurierbare Extraktion — Passe an, wie Felder extrahiert und ausgefüllt werden, über die Operaide-Oberfläche — keine Codeänderungen nötig. Extraktionsregeln, Feldbehandlung und Ausgabeformatierung an deine spezifischen Formulare anpassen.
Technische Details
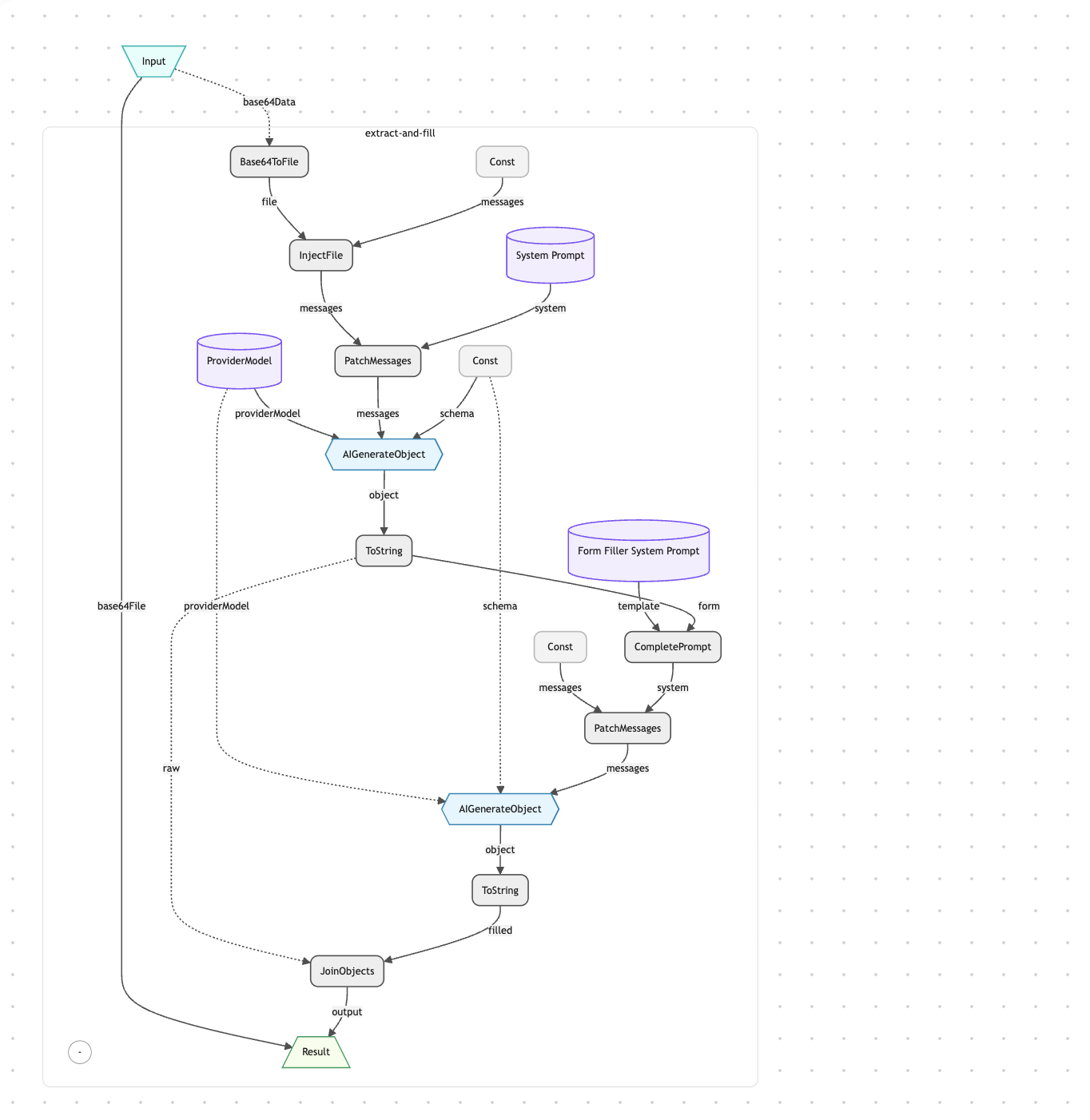
- Dateiinjektion in den LLM-Kontext — aktorBase64ToFile konvertiert die hochgeladene Base64-Data-URL in ein echtes File-Objekt mit automatisch erkanntem MIME-Typ und Dateinamen. aktorInjectFile wandelt es dann in eine FilePart-Nachricht um, die mit dem Vercel AI SDK kompatibel ist, und injiziert die Datei direkt in den Nachrichtenverlauf des LLM.
- Schema-erzwungene Generierung — aktorAIGenerateObject ruft das LLM mit einem strikten Zod-Schema (DocumentExtractionSchema) auf. Das Framework validiert die LLM-Ausgabe gegen das Schema — und garantiert typsichere Ergebnisse mit korrekten Feldtypen, Konfidenzwerten und Gruppierungen. Keine Nachbearbeitung oder manuelles Parsing nötig.
- Zweiphasige Pipeline — Phase eins extrahiert die rohe Formularstruktur aus dem Dokument. Phase zwei ruft relevante Unternehmensdaten aus der AgentDB ab, injiziert sie zusammen mit dem Extraktionsergebnis in einen Ausfüll-Prompt über aktorCompletePrompt und ruft aktorAIGenerateObject erneut auf, um die ai_filled_value-Felder zu befüllen. Beide Phasen verwenden dasselbe Schema für konsistente Typisierung.
- Reichhaltiges Feldtyp-System — Das Extraktionsschema unterstützt 14 Feldtypen (Text, Zahl, Währung, Datum, Checkbox, Radio, Select, Tabelle und weitere), hierarchische Feldgruppierungen, optionale Enums und Konfidenzwertung von 0 bis 1 — eine umfassende Darstellung jeder Formularstruktur.
- UI-Schema-Tags — Das [file-upload]-Tag im Eingabeschema rendert eine Dateiauswahl in der Operaide-Oberfläche. Das [textarea]-Tag bei Ausgabefeldern rendert mehrzeilige Anzeigebereiche für das rohe und ausgefüllte JSON — ermöglicht Seite-an-Seite-Überprüfung direkt in der Plattform.
Reaktor-Architektur
Die Document-Fill-App registriert zwei Reaktoren. Der Extrahieren-und-Füllen-Reaktor ist die vollständige Pipeline: Die hochgeladene Base64-Datei gelangt in aktorBase64ToFile, wird über aktorInjectFile in den Nachrichtenverlauf injiziert und fließt in aktorAIGenerateObject mit einem System-Prompt und dem DocumentExtractionSchema zur Feldextraktion. Unternehmenswissen wird aus der AgentDB abgerufen und zusammen mit dem Extraktionsergebnis in einen Ausfüll-Prompt über aktorCompletePrompt injiziert, dann an einen zweiten aktorAIGenerateObject-Aufruf übergeben, der die ai_filled_value-Felder befüllt. Abschließend kombiniert aktorJoinObjects die rohen und ausgefüllten Ergebnisse zu einer einzelnen Antwort. Der Dokumenten-Parsing-Reaktor ist eine einfachere Variante, die nur die Extraktionsphase durchführt — nützlich für Fälle, in denen kein Auto-Ausfüllen benötigt wird.
Bereit zur Auslieferung von KI
Das funktioniert?
Erfahren Sie, wie Operaide Teams dabei hilft, zuverlässige KI-Anwendungen schneller bereitzustellen. Vom Prototyp bis zur Produktion — mit vollständiger Kontrolle und europäischer Souveränität.

