Frag deine Dokumente

Contributors

Geschätzte Implementierungszeit
Verwendete Bibliotheken
- @operaide/ai
- @operaide/aktor
- @operaide/document
- @operaide/vector
- zod
LLM-Anbieter und -Modelle
- Azure GPT-4o-mini
- OpenAI text-embedding-3-small (embeddings)
- Configurable via settings
Externe Dienste
- None
TAGS
Introduction
Speise deine Dokumente, PDFs oder Daten aus externen APIs ein — und stelle dann Fragen in natürlicher Sprache. Die KI durchsucht deine Wissensdatenbank semantisch und antwortet basierend auf dem, was sie findet, mit Quellenangaben. Ein separater Admin-Chat ermöglicht die Verwaltung der Wissensdatenbank per Konversation: Inhalte aufnehmen, auflisten, inspizieren und löschen — alles ohne den Chat zu verlassen.
Business Impact
Herausforderung
Mitarbeiter verschwenden Zeit mit dem Durchsuchen von Dokumenten, Handbüchern, internen Wikis und verteilten Systemen, um Antworten zu finden, die in unstrukturierten Inhalten vergraben sind.
Lösung
Unternehmenswissen aus Dokumenten und APIs wird in eine durchsuchbare Wissensdatenbank eingebettet; ein KI-Assistent ruft relevante Passagen ab und beantwortet Fragen in Echtzeit.
Ergebnis
Sofortige, fundierte Antworten aus deinen eigenen Wissensquellen — kein manuelles Suchen oder veraltetes Stammwissen mehr.
Funktionsweise
- Wissensaufnahme — Speise PDFs, Dokumente oder Daten aus externen APIs ein. Inhalte werden automatisch verarbeitet und in einer durchsuchbaren Wissensdatenbank gespeichert — Upload per API oder direkt über den Admin-Chat.
- Batch-Verarbeitung — Nimm mehrere Quellen gleichzeitig auf. Das System verarbeitet jedes Dokument einzeln und liefert Statusberichte pro Element.
- Semantische Suche — Stelle eine Frage, erhalte die relevantesten Passagen aus deiner Wissensdatenbank — nach Relevanz sortiert und nach Metadaten filterbar.
- Wissens-Chat — Ein KI-Assistent, der deine Wissensdatenbank eigenständig durchsucht. Er entscheidet, wann gesucht wird, wonach gesucht wird, und kann seine Anfragen mehrfach verfeinern, bevor er eine Antwort liefert. Verfügbar über eine integrierte UI oder per API zur Integration in bestehende Systeme.
- Wissensdatenbank-Administration — Ein separater Admin-Chat ermöglicht die vollständige Verwaltung per Konversation: Inhalte hinzufügen, suchen, auflisten, Details inspizieren und löschen — alles in natürlicher Sprache.
Technische Details
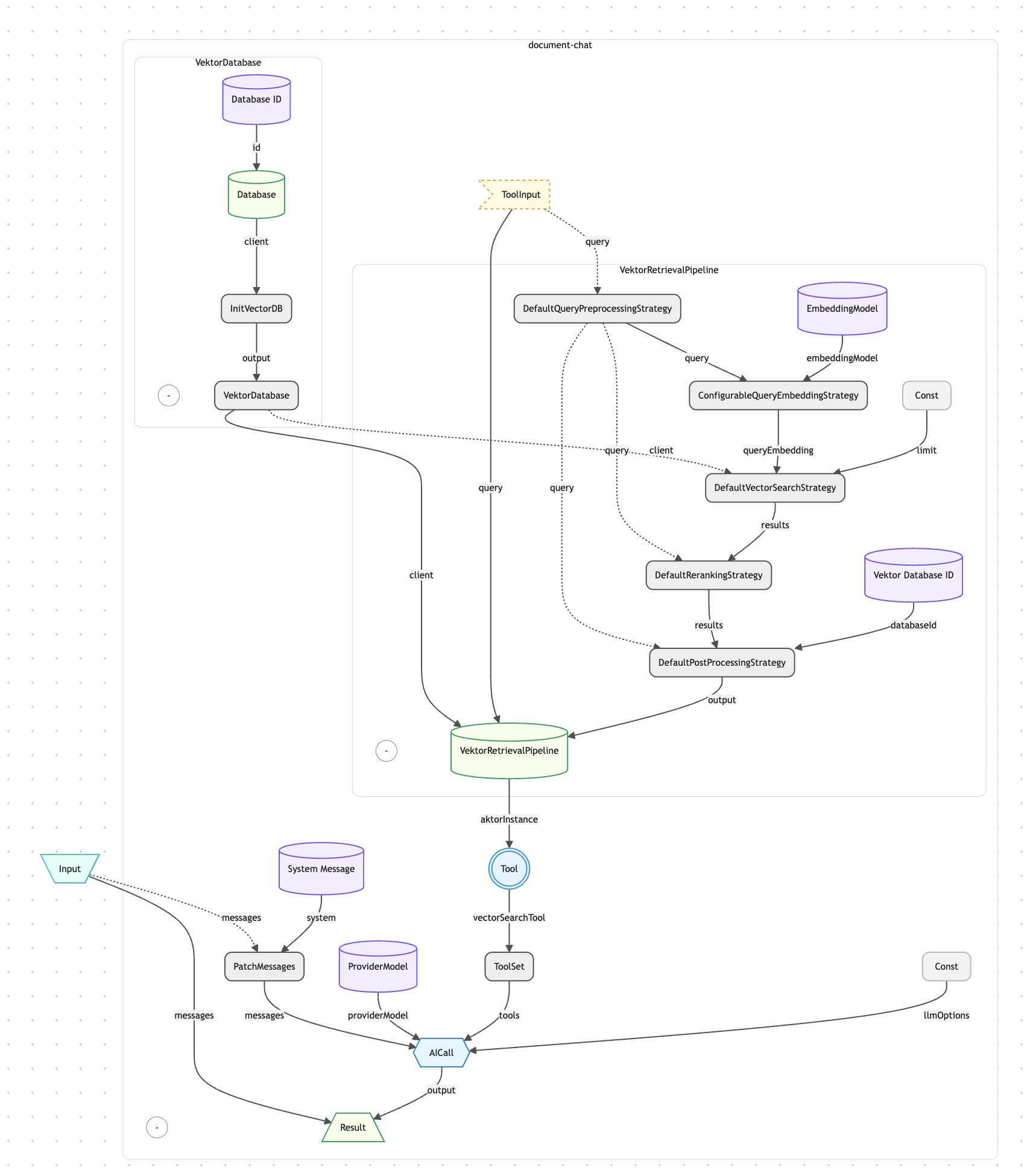
- Vektordatenbank mit @operaide/vector — aktorVektorDatabase initialisiert einen AgentDB-gestützten Vektorspeicher. Derselbe Datenbank-Client wird über alle fünf Reaktoren hinweg geteilt — Embedding, Retrieval, Chat, Admin und Batch-Verarbeitung lesen und schreiben alle in denselben Speicher.
- Embedding-Pipeline — aktorVektorEmbeddingPipeline übernimmt den gesamten Aufnahmefluss: Inhaltsverarbeitung (z.B. PDF über @operaide/document), Text-Chunking mit konfigurierbarer Überlappung, Embedding-Generierung (OpenAI text-embedding-3-small standardmäßig) und Batch-Speicherung. Ein eigener aktorBase64ToFile konvertiert hochgeladene Base64-Data-URLs in echte File-Objekte, bevor sie in die Pipeline gelangen.
- Retrieval als Tool — aktorToTool verpackt aktorVektorRetrievalPipeline in ein KI-aufrufbares Tool mit einem Zod-validierten Parameterschema. Der Datenbank-Client wird als Dependency injiziert — unsichtbar für die KI, die nur den query-Parameter sieht. Dieses Pattern trennt sauber, was die KI steuert, von dem, was das System bereitstellt.
- Mehrstufige Tool-Orchestrierung — aktorAICall wird mit max_steps: 5 konfiguriert, sodass die KI pro Durchlauf mehrfach Tools aufrufen kann. Sie kann suchen, Ergebnisse prüfen, ihre Anfrage verfeinern und erneut suchen, bevor sie eine finale Antwort generiert.
- Stream-Verarbeitung für Batch-Uploads — aktorForEachStream erstellt einen Stream aus einem Datei-Array, aktorVar hält die aktuelle Datei, und aktorStreamProcessor führt die Embedding-Pipeline für jedes Element aus. Dieses Pattern ermöglicht effiziente Mehrdatei-Verarbeitung, ohne alle Dateien gleichzeitig in den Speicher zu laden.
- Komponierbare Toolsets — Einzelne Tools werden mit aktorToTool erstellt, mit aktorToolSet gruppiert und mit aktorCombineToolSets zusammengeführt. Der Admin-Chat kombiniert ein Dateiverwaltungs-Toolset mit einem Such-/Upload-Toolset zu einem einzigen vereinheitlichten Set, das die KI nutzen kann.
Reaktor-Architektur
Das Knowledge-Chat-System besteht aus fünf Reaktoren, die sich eine einzelne Vektordatenbank teilen. Der Embedding-Reaktor und seine Batch-Variante übernehmen die Inhaltsaufnahme — Eingabe gelangt in aktorBase64ToFile, durchläuft aktorVektorEmbeddingPipeline (Parsing, Chunking, Embedding, Speicherung) und gibt Verarbeitungsstatistiken zurück. Der Retrieval-Reaktor exponiert aktorVektorRetrievalPipeline direkt für programmatische semantische Suche. Der Knowledge-Chat-Reaktor verpackt die Retrieval-Pipeline als Tool über aktorToTool und übergibt es an aktorAICall mit max_steps: 5 — die KI entscheidet eigenständig, wann und wie gesucht wird. Der Admin-Reaktor ist der komplexeste: Er extrahiert Dateien aus Chat-Nachrichten mit aktorFilesFromLastMessageAsFiles, richtet einen Stream-Prozessor für Batch-Embedding ein, erstellt fünf Tools (Verarbeiten, Suchen, Auflisten, Inspizieren, Löschen), führt sie mit aktorCombineToolSets zusammen und gibt der KI volle Wissensdatenbank-Verwaltungsfähigkeiten per Konversation.
Bereit zur Auslieferung von KI
Das funktioniert?
Erfahren Sie, wie Operaide Teams dabei hilft, zuverlässige KI-Anwendungen schneller bereitzustellen. Vom Prototyp bis zur Produktion — mit vollständiger Kontrolle und europäischer Souveränität.

